Flow Control簡單講就是流量控制,其主要目的就是避免通訊的雙方資料被掉包,那為何資料會掉包呢?我們想像一個情境,通訊一定是至少兩人以上互相傳送資料,互相傳送資料雙方硬體不一定會一樣,所以在效能上也會不一樣,若當接收端來不及處理已接收到資料時,若沒有通知對方暫停傳送資料,因而造成對方持續送資料,這樣就會產一種現象,就是接收端會將收進來的資料丟棄,或者不接收對方送過來的資料,因而造成資料的留失,所以我們就使用流量控制的部分來確保資料不要留失。其實其中的做法也不是太難,就是利用一個機制來通知對方不要送資料就好了,而問題在於以前這種的控制都由軟體來做,但是最後還是控制使用硬體來通知對方,在控制硬體送出訊號給對方會需要一些時間處理,而這段時間長短是無法預測的,並且對方還是在繼續傳送資料,假如這段時間過長,就會造成和没有流量控制一樣的情形,也因此為了解決這個問題,現在就有人改用硬體來處理這個問題,就可以大大降低這個問題的產生,但是若要真正有效發揮硬體的功能是需要修改軟體的,所以以下我們會來說明如何修改軟體。
Serial Port的流量控制方式
RS232的流量控制方式有兩種,一種稱為軟體流量控制方式,另外一種就是所謂的硬體流量方式,什麼是軟體流量控制方式,其控制方式就是將控制訊息加到資料之中,用另外一個方式說明,就是當接收端無法收資料時就送一個字元Xoff (0x13)給對方,可以收的時候就送一個字元Xon (0x11)給對方,所以軟體控制的方式有幾種限制,首先是在傳送的資料不可以包含這兩個字完,否則將會嚴重破壞流量控制的正常運行,另外一個限制就這兩個字元必須是要即時被送出,若和要送給對方的資料一起排隊的話,有可能會延誤流量控制的時間點,因而造成流量控制的失敗。
另外一種的流量控制方式為硬體方式,其作法是必需另外再接兩條線,一條為RTS至對方的CTS,因為是雙向的所以另外一條就是我的CTS接至對方的RTS,另外的說法雙方都會增加兩隻腳為RTS及CTS,其做法很簡單就是當接收端資料快滿的時候,將RTS設為low,一直到可以接收資料時再將RTS拉為high,相對的傳送端會隨時檢查CTS,當它為low時就停止送資料,當它為high時就開始送資料。
RS232的上層控制驅動程式為tty_io,而這層則會負責流量控制,當需要做相對流量控制的行為時,它會呼叫你的RS232驅動程式作動作,所以只要做相對的動作即可,而這個動作則是前一篇文章-serial port device driver中所提的throttle & unthrottle這兩個call back function。
有什麼問題嗎?
若按照前面所提的,在寫串列式驅動程式的時候有什麼問題?看是沒有問題,但問題就在後面,因為現在的UART越做越好,所以就將流量控制的動作直接由IC本身實現,就不需要軟體來處理,IC實現有它的好處,因為它是由硬體來處理,所以反應的時間會非常快,能夠避免軟體處理時需要冗長的時間,可能會造成反應不及而讓流量控制無效。在找出問題之前我們先看以下的圖:
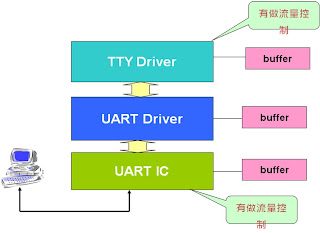

以上為驅動程式的架構圖,通常每一層驅程式都會有自已的buffer來存放收送的資料,而前面有說過在tty_io層會做流量控制,而它是如何判斷何時需要做流量控制呢?當然是依照它自已的buffer來做判斷,快滿的時候就叫對方不要送資料,buffer已被讀完則通知對方可以送資料,問題在於當上層的buffer滿並不代表低層IC上的buffer已滿,如此一來有一種情境將會發生,底層的IC buffer已滿,因為有支援流量控制,所以IC已經主動通知對方不要送資料,可是這時候因為上層的資料未滿,或者剛到低水位,所以通知低層送出通知對方可以送資料,如此一來將會弄亂底層的流量控制,簡單的說明就是上層的buffer水位和底層是不會同步的,用另外一種方式來看待這個問題,其實這麼多層的驅動程式,只要其中有一層做流量控制即可,這時候當然讓最低層的IC來處理即可,因為可以反應最快,並且因為由IC自行處理,所以可以減輕CPU的負擔,所以在有IC支援流量控制時RS232的驅動程式,應該如以下的寫法將會是比較好的:
static void uart_throttle(struct tty_struct *tty)
{
…………
disable_IC_receiving_and_receiving_interrupt();
………………..
}
static void uart_unthrottle(struct tty_struct *tty)
{
………………
enable_IC_receiving_and_receiving_interrupt();
…………………
}
没錯一個簡單的動作,就是在throttle的callback function中停止收資料就好了,因為如此一來將會造成IC buffer到達高水位而讓IC自動作成流量控制的行為即可,另外unthrottle的callback function中再一次啓動收資料即可,因為將IC中的buffer讀走而達低水位時,IC將會再次自動做出流量控制,如此一來上層可以不用知道低層IC的buffer使用情形,也不會弄亂IC的流量控制,這是在IC支援流量控制時所要做的修正。
